Real-Time Data Processing using AWS
Real-time data is something that is being updated on a near-to-real-time basis. We will be using different AWS services to create a data pipeline that will be used to handle and integrate this real-time data and finally load it into a Redshift Data Warehouse.
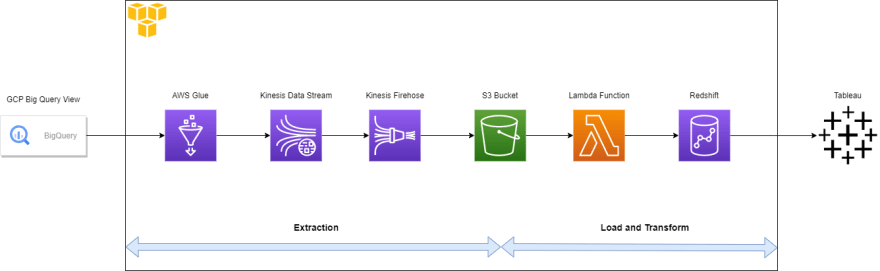
We will be considering the following architecture for this scenario.
Google Big Query View
Google Big Query View is a service provided by Google Cloud Platform. We are considering this view as a source for us. We are assuming the data in the view is being updated at a certain rate. This view should contain relational data that will use to perform real-time integration.
AWS Glue Job
We will be using AWS Glue Job as an extraction script for this scenario. For this, the first thing needed is to create a connection to Google Big Query View. Following are the steps to be followed for this purpose:
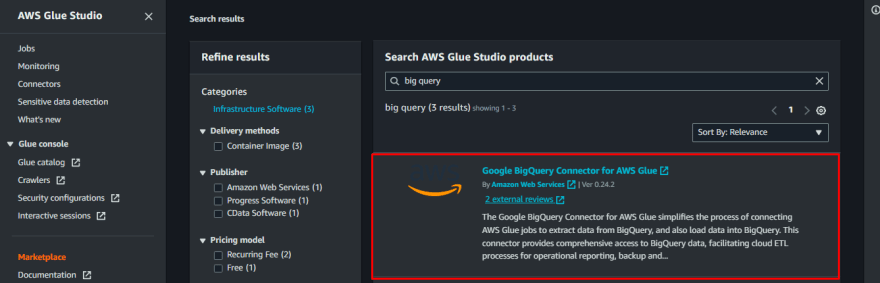
Subscribe Connector
First, we need to go to connectors in AWS Glue to subscribe to a connector for Google Big Query. The following image shows how we can subscribe to a connector for Google Big Query.

Create a Connection
After subscribing to the connector for Google Big Query view, we can set up a connection by using the JDBC URL and the connection credentials for the View.
For this purpose, we are using a secrets manager to store the JSON credentials and use them as a secret. After setting up the JDBC connection, we can access the Big Query view either using Scala or Pyspark in the Glue Job Script.

This is a sample script of how we can access the data of the view from AWS Glue Job. For this, we need the “parentProject”, “table”, and the “connectionName” we made earlier.

After the data has been extracted, we can convert it into a pyspark dataframe. We can now access the dataframe and put it into an active Kinesis Data Stream.
We are using boto3 to initialize the kinesis data stream. We should have already created a kinesis data stream for this purpose.

AWS Kinesis Data Stream
Kinesis Data Stream can be used to ingest large streams of data in real-time. In this scenario, we are putting records in the kinesis data stream at a certain rate from the Glue Job. We have to make sure that the data stream must be always active in order to ingest data.
Kinesis data stream also uses shards, that allows multiple consumers to consume the records by distributing it.
When record is put into the data stream, it is distributed among the shards that are defined on the basis of the partition key.
Shards are the reason for the rate normalization in the kinesis data stream, that’s why it helps in higher throughput and scalability for data streaming purposes.
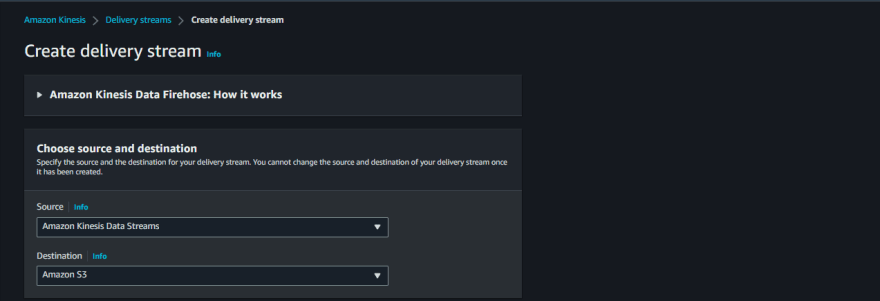
Following image shows how a data stream can be created in the AWS console.

AWS Kinesis Firehose
Kinesis Firehose is a delivery stream in the kinesis platform along with kinesis data stream. This is used to get the records from the data stream and deliver it to a destination.
The main purpose of the kinesis Firehose is to ingest the streaming data so that we can focus more on the analytics rather than the data pipeline. It is used to process data that is being produced continuously and needs to be stored and analyzed quickly. In this scenario we are dealing with realtime data, so Firehose would be the best option to process and store the real-time data.
The following image shows a step to make a kinesis Firehose, for this scenario, our source is going to be a kinesis data stream and the destination is going to be the s3 bucket. We can encrypt the data, transform the format of the data and do quick ingestion using this delivery stream.
AWS S3 Bucket
AWS S3 bucket stands for Simple Storage Service. This can be considered as the data lake where we will be storing all the ingested data. Kinesis Firehose will be responsible to deliver the data in the desired format to the s3 bucket. A
nd, on the basis of the event of the file delivery on the s3 bucket, we can trigger a lambda function that will be responsible to load the data into the Redshift tables.
The following image shows the steps of creating a s3 bucket. After the bucket has been created, it can be used to trigger the lambda function and perform further data integration.

Lambda Function
The lambda function is a popular service provided by AWS. It is a serverless, event-based service widely used for computing purposes.
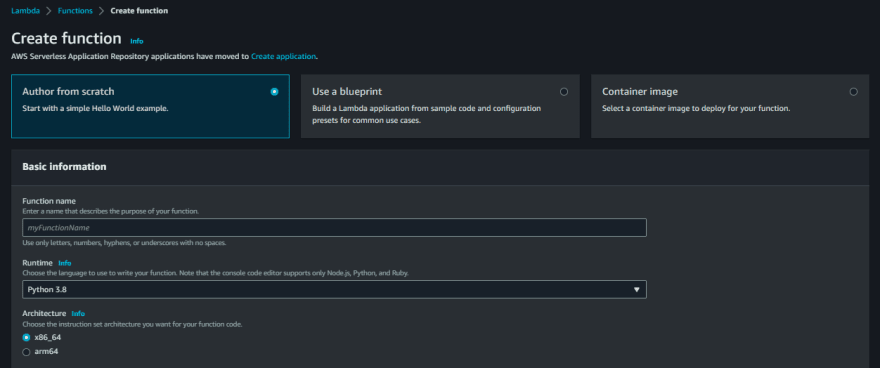
In this scenario, we are using the lambda function to get the data that was put in s3 bucket and load it into Redshift tables. The following image shows a step to make a lambda function.
Create a connection to AWS Redshift
We can use a Python environment for this purpose and create a connection to AWS Redshift. The following python script shows a way to create a connection to AWS Redshift. After a connection has been created, we can use this script to execute by sending a SQL statement to this script and cluster information as constants.

Load data from S3 Bucket to Redshift Tables
After a connection has been created, using the event that has triggered the Lambda function, we can access the file and load it to any of the Redshift Tables. The following Copy command provides us the facility to load the data from the s3 bucket into a Redshift Table. A proper IAM role is needed for this purpose to load the data into the Redshift table.

AWS Redshift
AWS Redshift is a Data Warehouse service provided by AWS. Redshift is a petabyte scaled Data Warehouse so, it can store a huge amount of relational data. After the data has been inserted into Redshift Tables, we can process it through the lambda function for further transformation. We can create a cluster for this purpose and create multiple schemas for this like STG, TMP, and TGT. After data has been loaded in the desired destination, views can be created on top of the target tables and then metrics out of it.
Finally using tools like Tableau, we can create interactive reports.





![[SOLVED] How to Disable Edge Alt + Tab Settings in Windows 10](https://awan.com.np/wp-content/uploads/2021/07/How-to-Remove-Edge-Browser-Tabs-From-AltTab-on-Windows-10-1-768x430.png)